數據孤島與用戶數據的價值覺醒
2022年,我(Anna)曾提出一個設想:建立一個由用戶擁有的基礎模型,其訓練數據來源不是公開抓取的網絡信息,而是私有數據。 儘管利用公開數據(如維基百科、4chan)訓練基礎模型有其價值,但要實現飛躍,需要高質量的私有數據——那些存在於需要授權或登錄才能訪問的封閉平台(如 Twitter、私人消息、公司內部信息)中的數據。
如今,這個預測正逐步成為現實。 Reddit 和 Twitter 等公司已經意識到其平台數據的價值,紛紛收緊了開發者API(1, 2),以阻止其他公司免費使用其文本數據訓練基礎模型。
這與兩年前的情況截然不同。正如風險投資人 Sam Lessin 所言:「[平台] 過去只是把這些垃圾扔在後面,沒有人看管。突然之間,人們意識到,哦,該死,這些垃圾是金子!我們擁有很多,必須鎖好垃圾箱。」 例如,GPT-3 的訓練數據集 WebText2,匯總了 Reddit 上所有點讚數超過 3 的鏈接文本(3, 4)。在 Reddit 啟用新的 API 後,這種做法已不再可行。
互聯網正在變得越來越不開放,各平台紛紛築起高牆,保護其珍貴的訓練數據。
用戶擁有的基礎模型:一個新的數據金礦
儘管開發者無法再大規模獲取平台數據,但得益於數據隱私法規,個人仍然可以跨平台訪問和導出自己的數據(5, 6)。 平台限制開發者 API,而個人用戶仍能訪問自身數據——這就提供了一個機會:一億用戶是否可以導出其平台數據,創建世界上最大的數據寶庫? 這個數據寶庫將匯集大型科技公司和其他公司收集的所有用戶數據,而這些公司通常不願分享這些數據。 這將是迄今為止最大、最全面的訓練數據集,比用於訓練當今領先基礎模型的數據集大 100 倍。

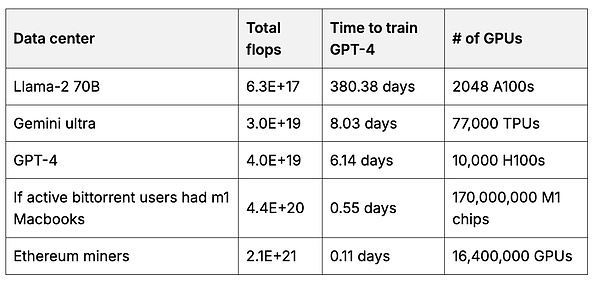
數據與算力的集結:超越巨頭的可能性
基於此,用戶可以創建一個用戶擁有的基礎模型,其使用的數據量將超過任何一家公司所能彙集的數據。 訓練基礎模型需要大量的 GPU 計算。 但每個用戶都可以利用自己的硬件幫助訓練模型的一小部分,然後將這些部分合併在一起,創建一個更大、更強大的模型(7, 8, 9)。 當激勵機制到位時,用戶可以匯集龐大的計算資源。 例如,以太坊礦工的總計算量是訓練領先基礎模型的 50 倍。
數據DAO:重塑AI所有權與收益分配
為該模型做出貢獻的用戶將集體擁有並管理該模型。 他們可以在使用模型時獲得報酬,甚至可以根據他們的数据对模型的改进程度按比例获得报酬。 集體可以制定使用規則,包括誰可以訪問該模型以及應該實施哪種控制。 也許每個國家/地區的用戶都會創建自己的模型,代表他們的意識形態和文化。 或者,也许一个国家并不是正确的分界线,我们将看到一个世界,每个网络国家都有自己的基于其成员数据的基础模型。
我鼓勵您花時間思考一下您希望擁有哪些基礎模型的一部分,以及您可以從使用的平台貢獻哪些訓練數據。 您可能擁有的數據比您意識到的還要多——您的研究論文、未發布的藝術品、您的 Google 文檔、您的約會資料、您的醫療記錄、您的 Slack 消息。 將這些數據整合在一起的一種方法是通過個人服務器,這使您可以輕鬆地將您的私人數據與本地 LLM 一起使用。 將來,您的個人服務器還可以訓練您擁有的用戶基礎模型的一部分。
基礎模型傾向於壟斷,因為它們需要在數據和計算方面進行大量的前期投資。 我們很容易選擇簡單的選項:盡我們所能地使用落後幾代的開源模型,即大型人工智能公司的殘餘。 但我們不應該滿足於落後幾代,只吃剩飯剩菜! 作為用戶,我們應該創建我們自己的最佳模型——我們擁有實現這一目標的數據和計算能力。
隨著人工智能越來越有能力完成有價值的經濟工作,一場巨大的經濟轉變正在發生。 大型科技公司已經根據您的公開工作、寫作、藝術作品、照片和其他數據以及其他人的數據訓練了人工智能模型,並開始每年賺取數十億美元(1)。 他們現在正在追逐您在公共互聯網上無法獲取的數據,從 Reddit 等公司購買您的私人數據,這樣他們就可以將人工智能的收入增加到每年數萬億美元(2, 3)。
您難道不應該擁有由您的數據幫助創建的AI 模型的一部分嗎?
技術架構:數據DAO如何運作
這就是數據 DAO 的作用所在。 數據 DAO 是一個去中心化的實體,允許用戶匯集和管理他們的数据,并用代表特定數據集所有權的數據集特定代幣獎勵貢獻者。 它有點像数据的工會。 這些數據集可以復制甚至超越大型科技公司以數億美元出售的數據集 ( 4 )。 DAO 对数据集拥有完全控制权,可以选择将其出租或出售匿名副本。 例如,Reddit 數據甚至可以用來播種新的、用戶擁有的平台,包括好友、你過去的帖子和其他數據,這些數據可以在新平台上隨時使用。
如果您對技術細節感興趣:數據 DAO 有兩個主要組成部分:1)鏈上治理,通過數據貢獻獲得代幣;2)安全服務器,使用公鑰-私鑰對進行加密,社區擁有的數據集駐留在該服務器中。 要做出貢獻,您首先要驗證數據以證明所有權並估計其價值。 然後,使用服務器的公鑰在瀏覽器中加密數據,並將加密數據存儲在雲中。 只有當 DAO 批准授予訪問權限的提議時,數據才會解密。 例如,它可以允許 AI 公司租用數據來訓練模型。 您可以在此處閱讀有關 Vana 網絡架構的更多信息,該網絡旨在實現數據集和模型的集體所有權。
集體行動:通往用戶擁有的互聯網之路
數據 DAO 不僅使用戶受益,還推動了 AI 的發展,使像開源軟件一樣構建 AI 成為可能,讓所有做出貢獻的人受益。 開源 AI 正在努力尋找可行的商業模式:支付 GPU、數據和研究人員的費用非常昂貴。 而且,一旦模型訓練完成,如果它是開源的,就無法收回這些成本。 數據 DAO 的技術架構可以應用於模型 DAO,用戶和開發人員可以貢獻數據、計算和研究以換取模型的所有權。
當今社會的默認選項是允許大型科技公司獲取我們的數據,並用它來訓練為我們工作的人工智能模型。 他們從這些人工智能模型中獲利,因為我們被用我們的數據訓練的模型所取代。 這對社會來說是一筆非常糟糕的交易,但對大型科技公司來說卻是一件好事。 防止這種情況發生的唯一方法是採取集體行動。 數據就是貨幣,集體數據就是力量。 我鼓勵你參與:世界上第一個專注於 Reddit 數據的數據 DAO 今天在 Vana 網絡上線。 通過打破少數特權階層控制的數據護城河,數據 DAO 開辟了一條通往真正用戶擁有的互聯網的道路。
發佈留言